Overview
13 languages
Code-switching-aware SFT
GRPO curriculum RL
Medical reasoning
A curriculum-guided RL framework (code-switching-aware SFT + GRPO) for reliable multilingual medical reasoning.
We evaluate multilingual medical reasoning using verifiable open-ended queries, measuring both logical correctness and language consistency across languages.
A large-scale benchmark spanning high-, mid-, and low-resource settings, including underrepresented languages such as Amharic, Yoruba, and Swahili.
A two-stage training framework that jointly improves reasoning correctness and linguistic fidelity, with curriculum progression from high- to low-resource languages.
Extensive automatic and human evaluation shows consistent gains over strong baselines and improved generalization, including in low-resource settings.
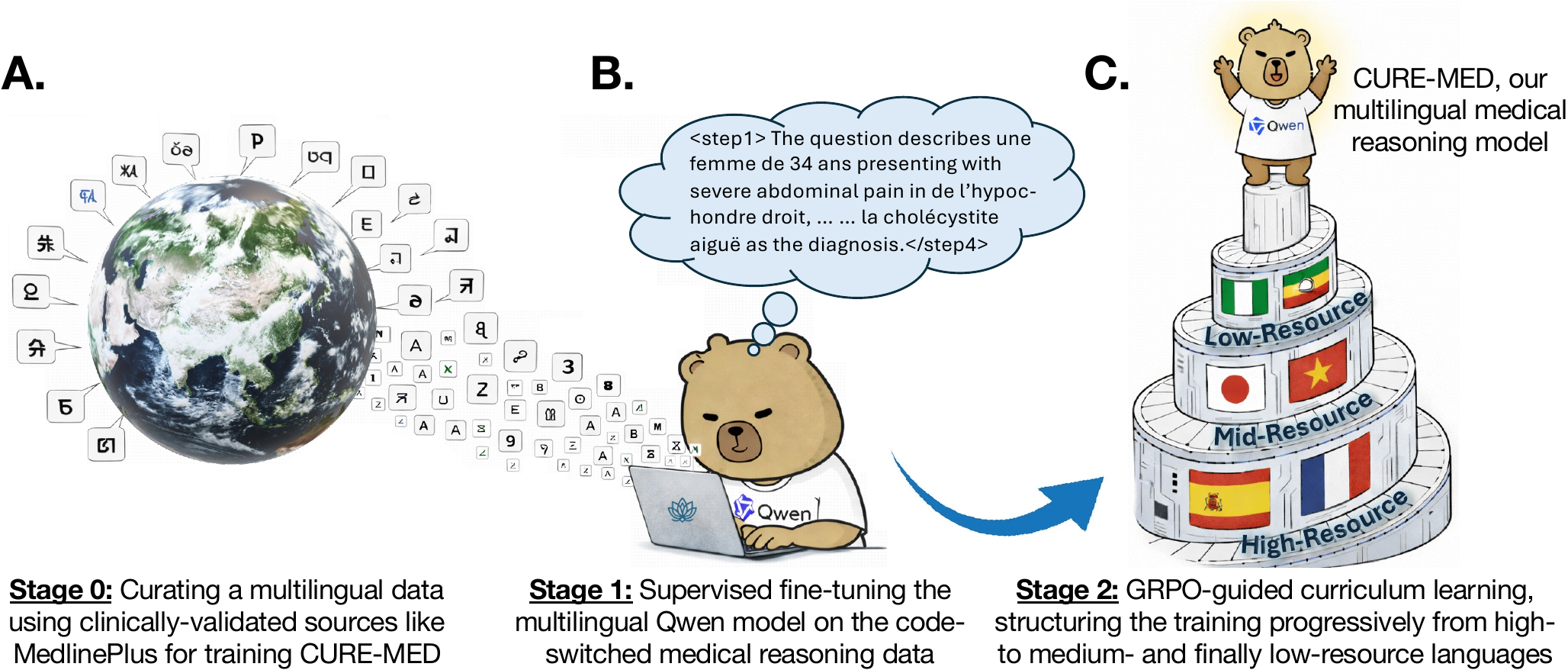
CURE-Med combines a clinically grounded benchmark with curriculum-guided reinforcement learning to improve medical correctness while keeping the final answer in the user’s language.
We construct CUREMED-BENCH from clinically validated sources and generate multilingual medical reasoning queries. Native speakers and medical experts verify clinical correctness and language consistency across all languages.
We warm-start the model with supervised fine-tuning on a code-switched reasoning dataset across the 13 languages. This stabilizes multi-step reasoning before reinforcement learning.
We use a verifier-driven reward that encourages correct clinical conclusions while enforcing target-language fidelity and a clean, structured response format.
After warm-starting, we apply GRPO with a language-resource curriculum, training progressively from higher-resource to lower-resource languages while retaining prior skills to reduce forgetting.
▍
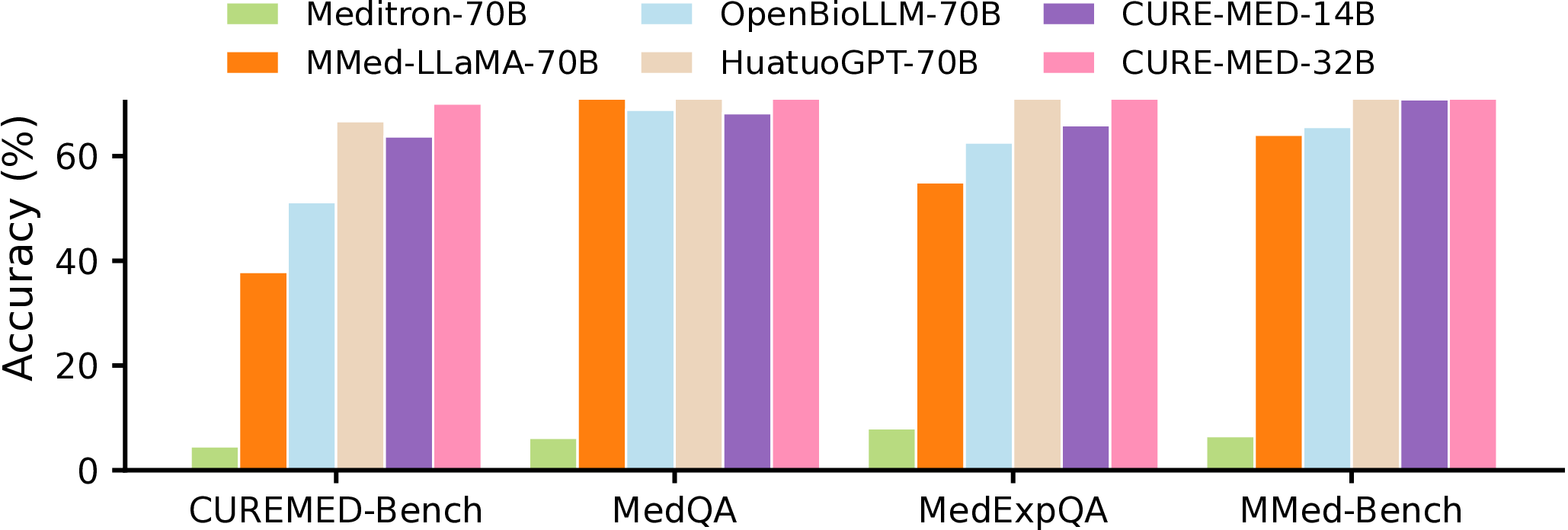
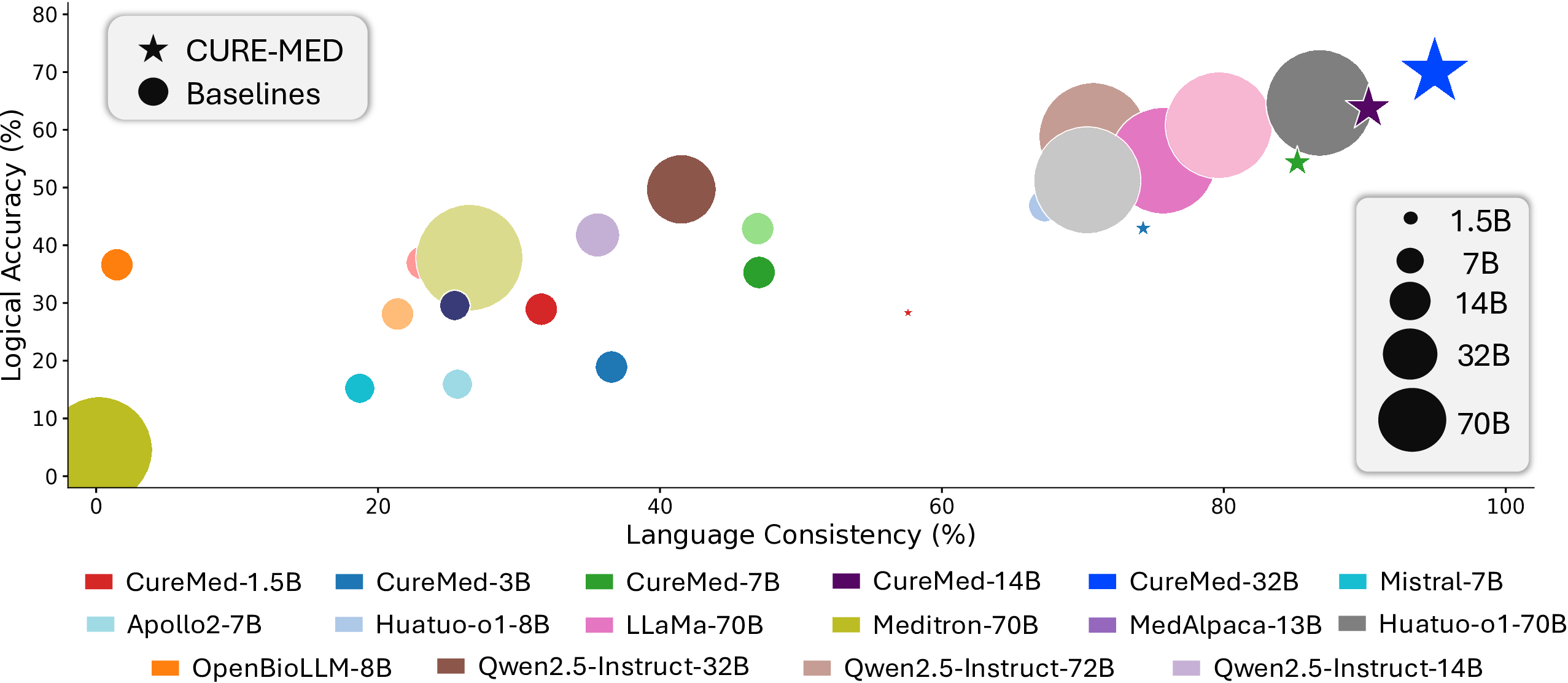
CURE-Med improves language consistency and logical accuracy across model sizes. Beyond CUREMED-BENCH, it also transfers out-of-domain to other multilingual medical benchmarks and outperforms strong medical LLM baselines. Select a model size to view gains vs. the base model, then inspect the figures.
If you use CURE-Med or CUREMED-BENCH, please cite our arXiv paper: arXiv:2601.13262.
@article{onyame2026cure,
title={CURE-Med: Curriculum-Informed Reinforcement Learning for Multilingual Medical Reasoning},
author={Onyame, Eric and Ghosh, Akash and Baidya, Subhadip and Saha, Sriparna and Chen, Xiuying and Agarwal, Chirag},
journal={arXiv preprint arXiv:2601.13262},
year={2026}
}Built with curiosity — scaling trustworthy medical reasoning across diverse languages, for the benefit of all.
© · CURE-Med · Project page